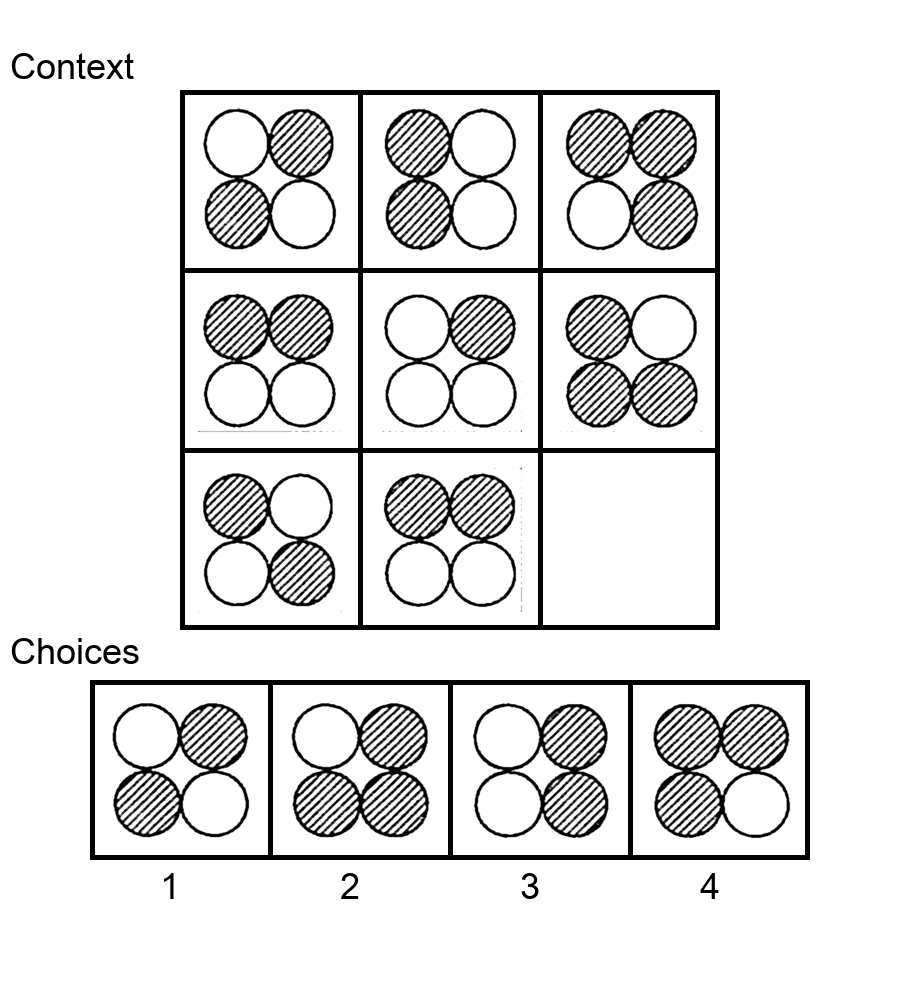
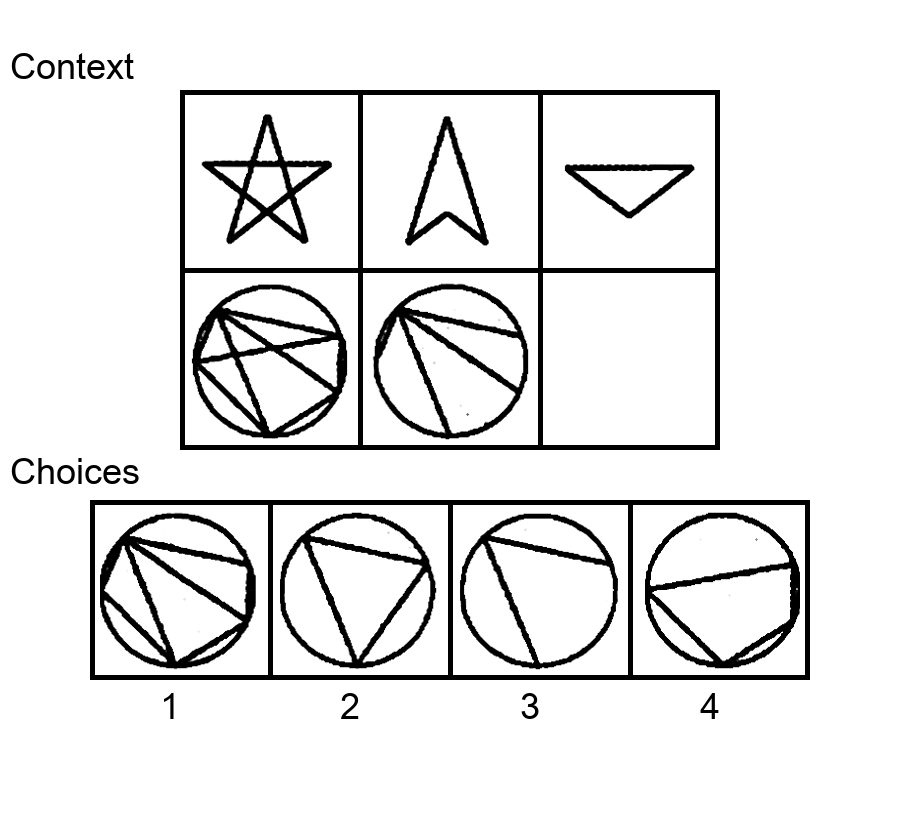
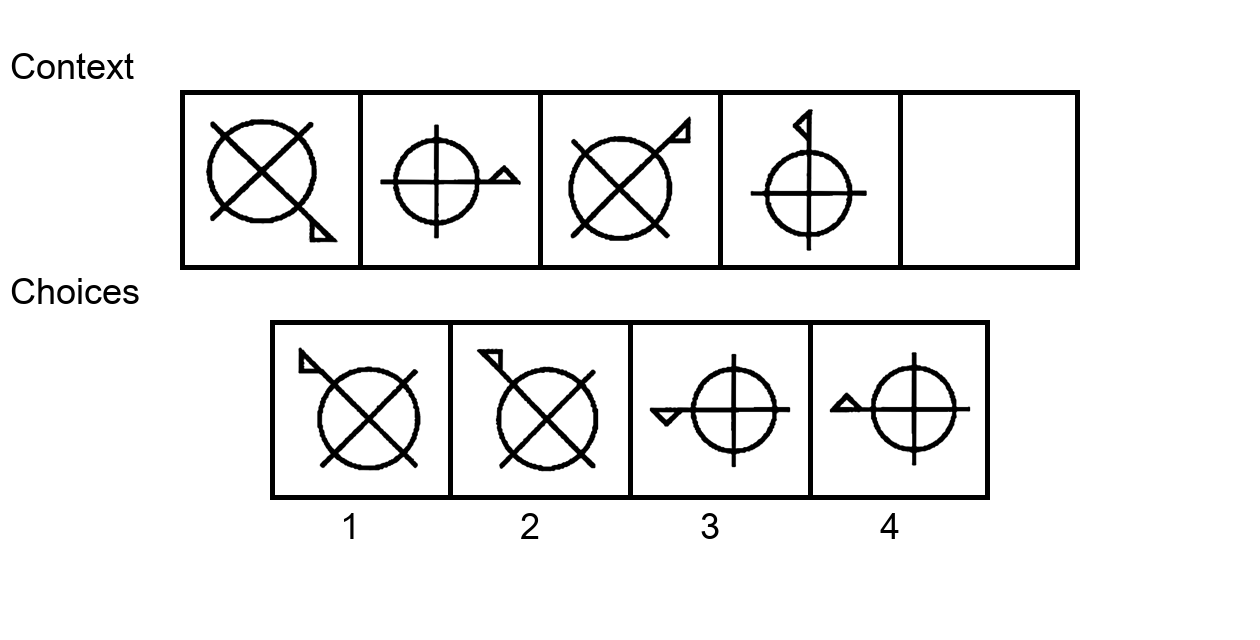
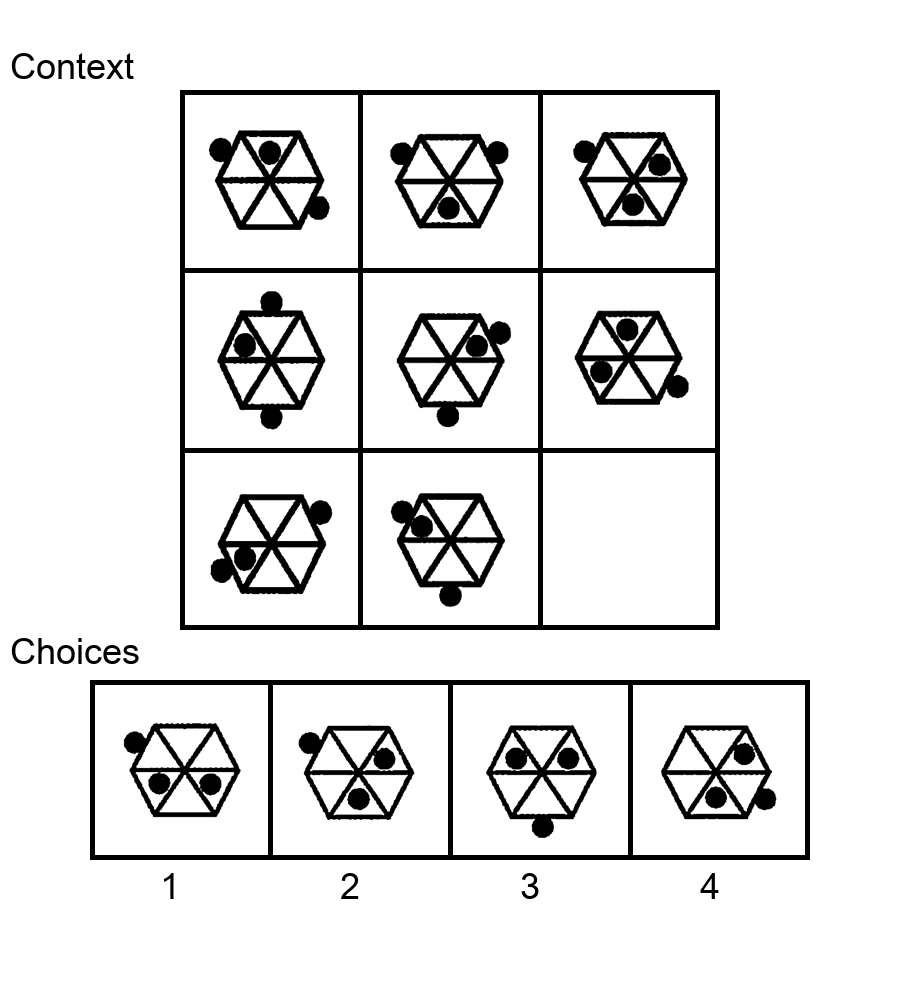
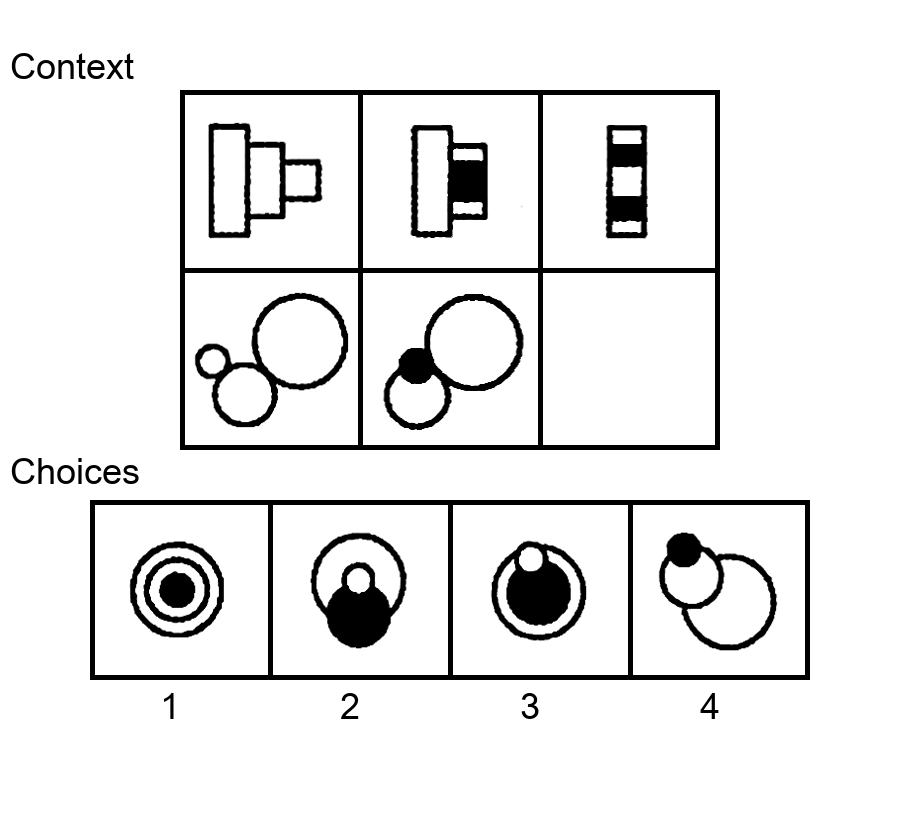
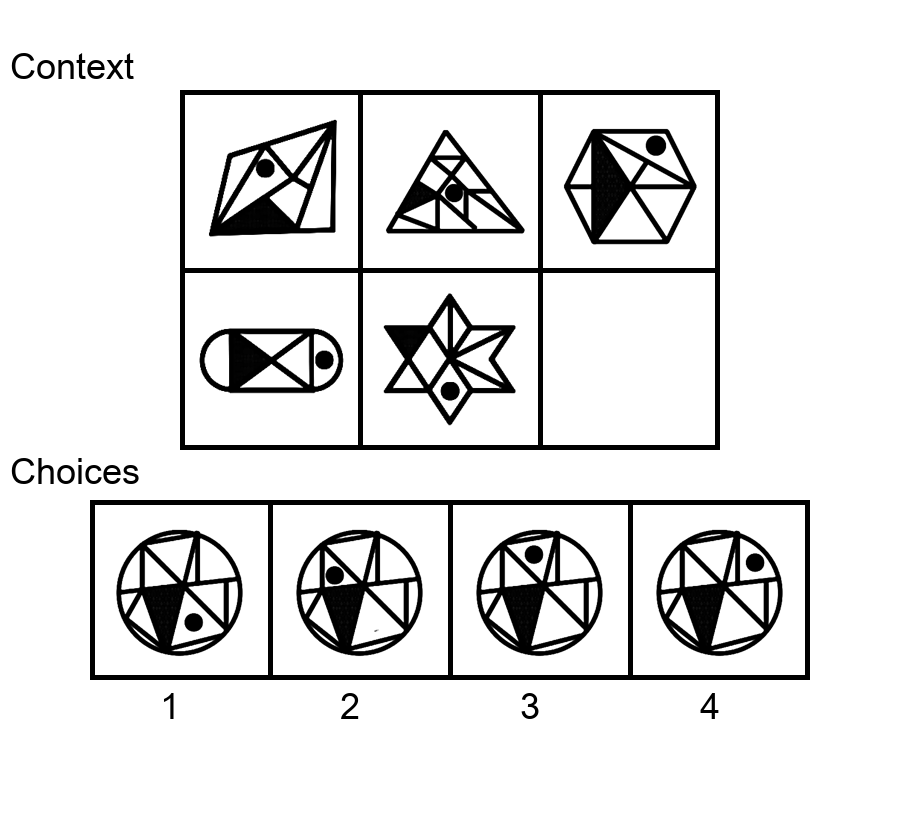
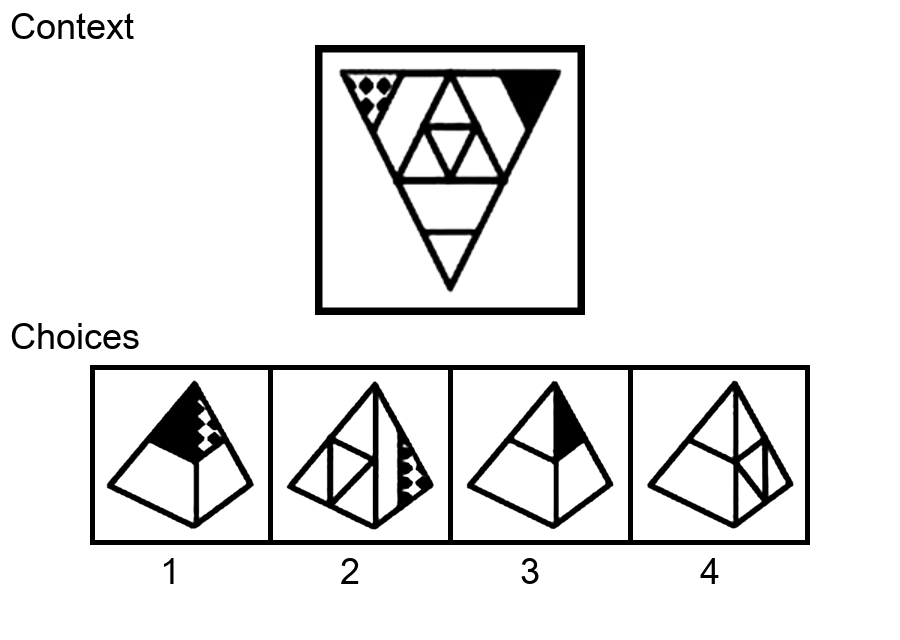
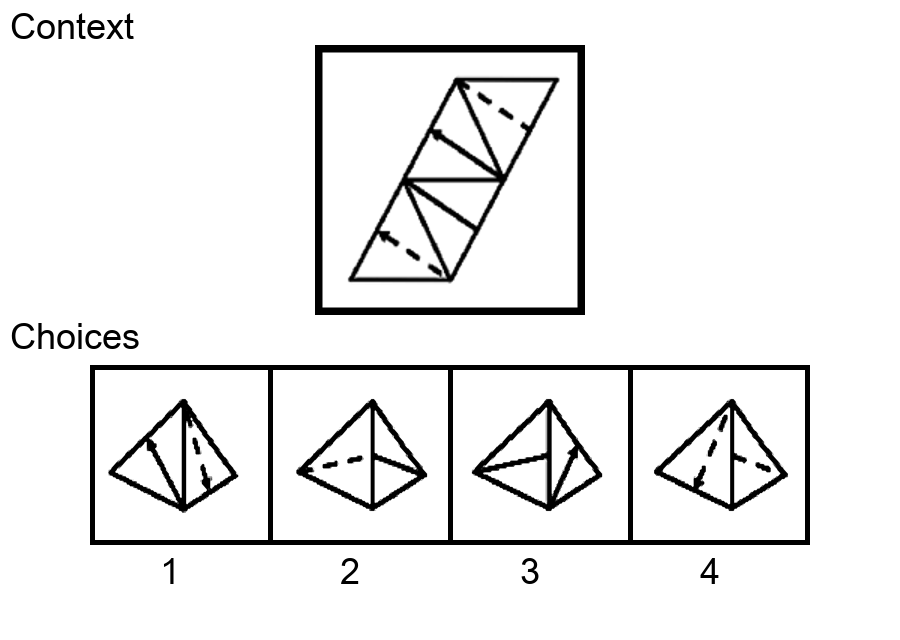
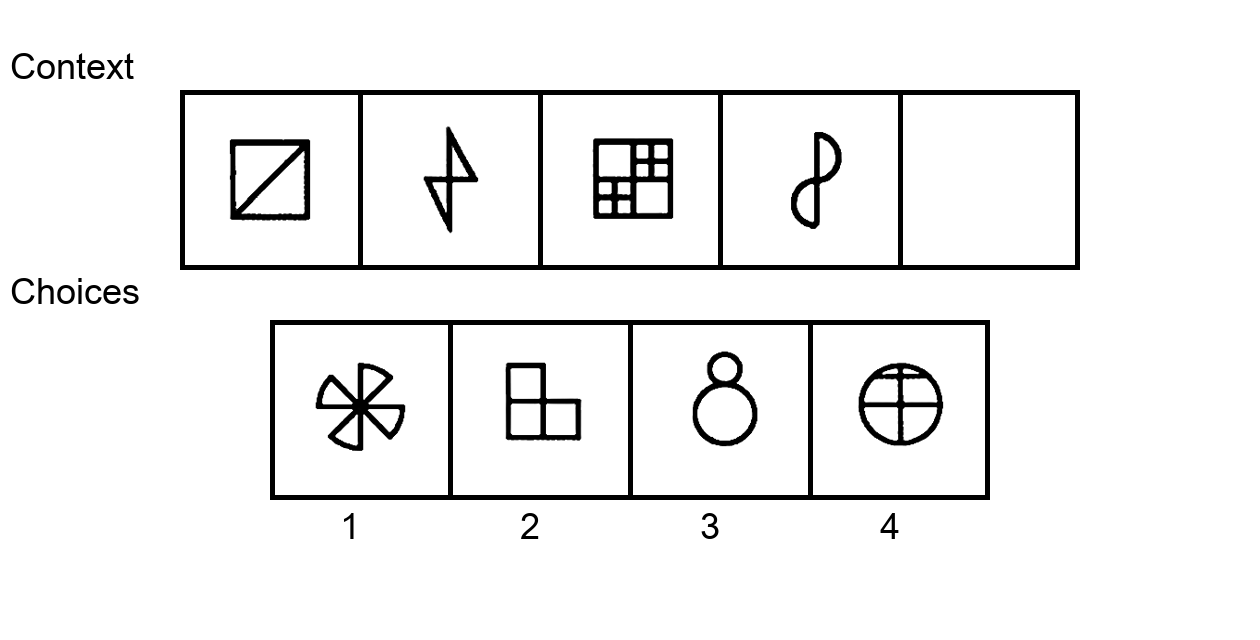
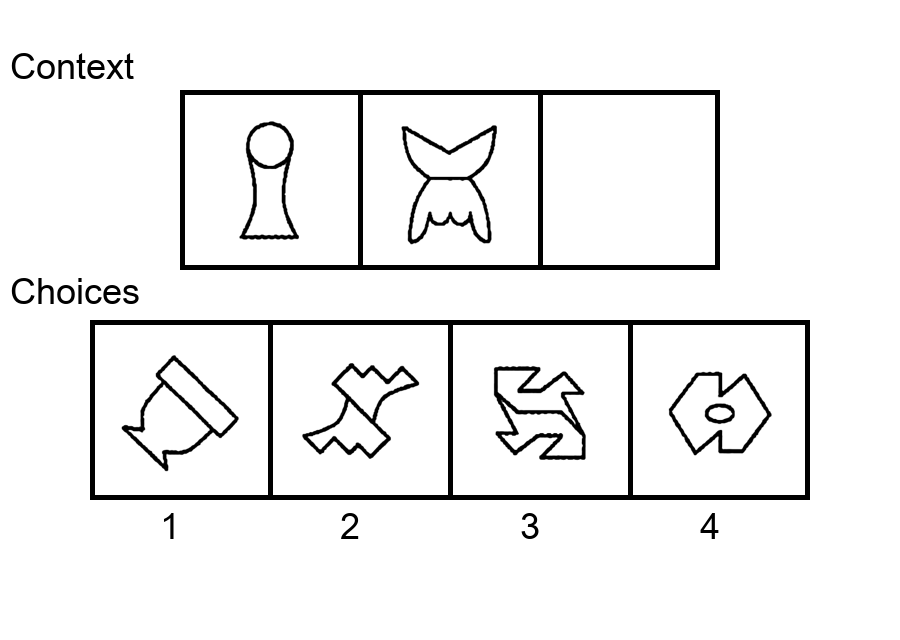
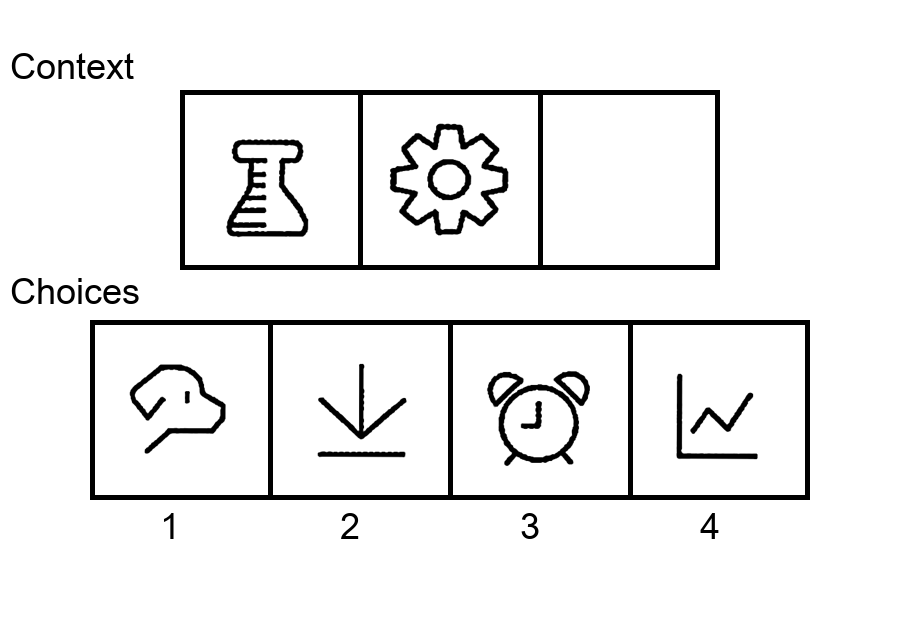
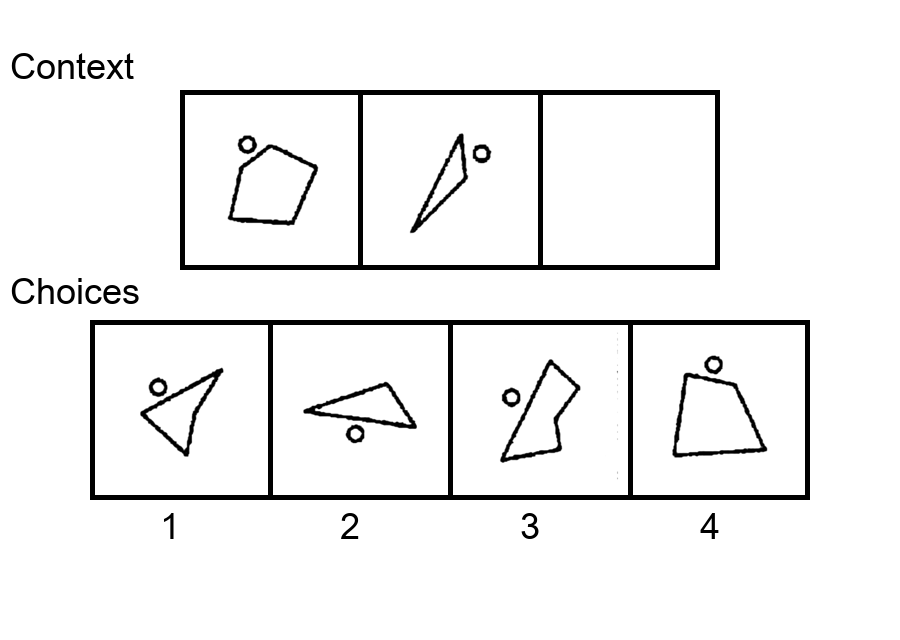
While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether
they possess abstract visual reasoning abilities remains an open question.
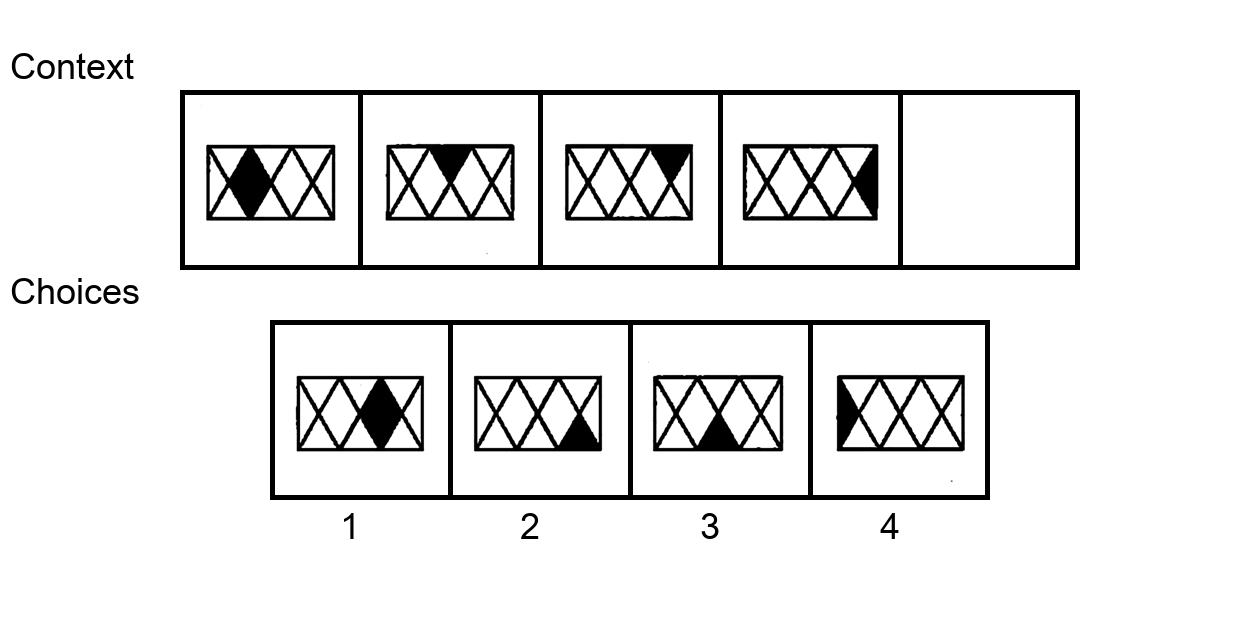
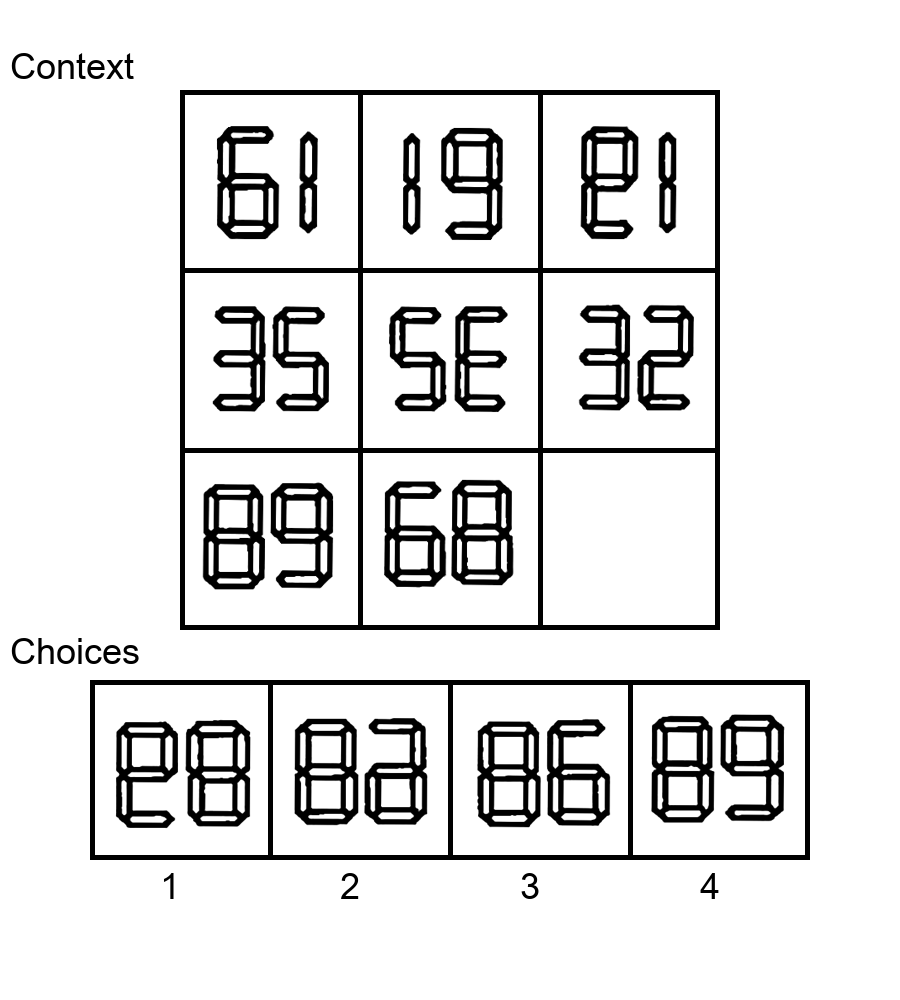
Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems
require finding high-level patterns (e.g., repetition constraints) that control
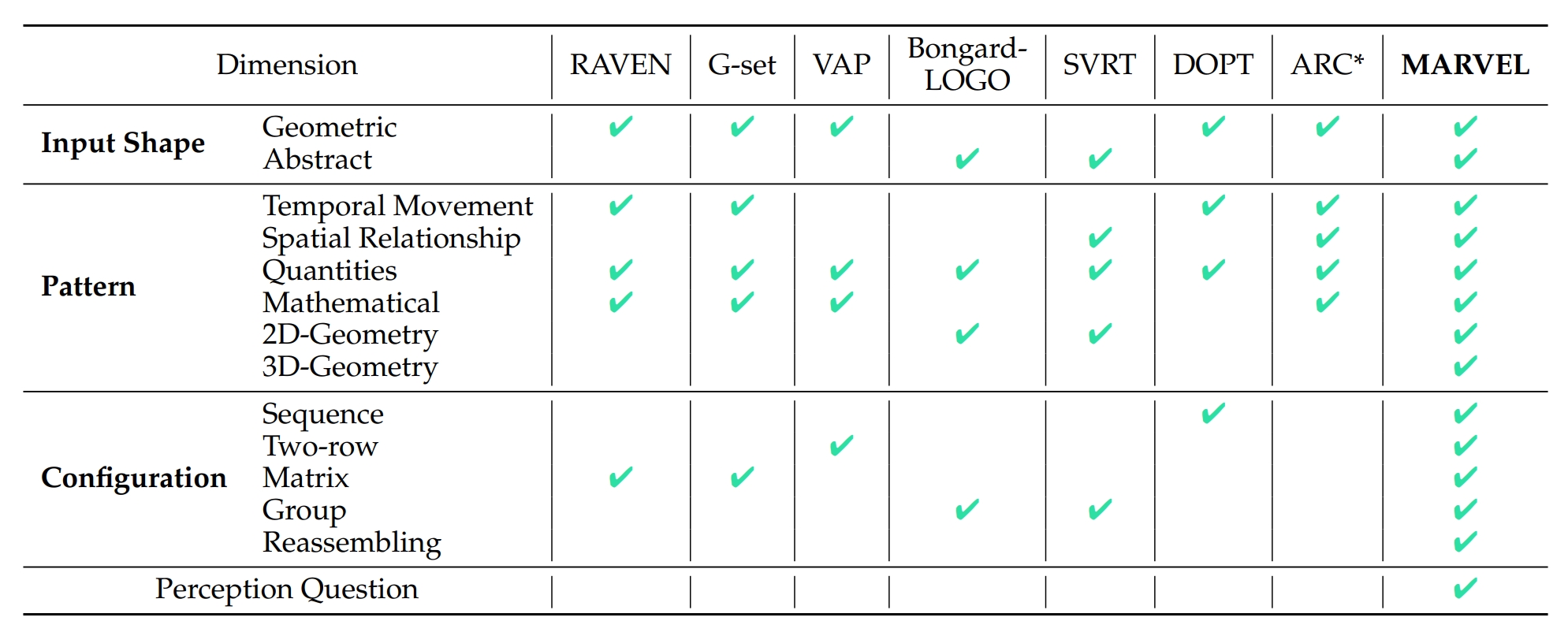
the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set
of patterns (addition, conjunction), input shapes (rectangle, square), and
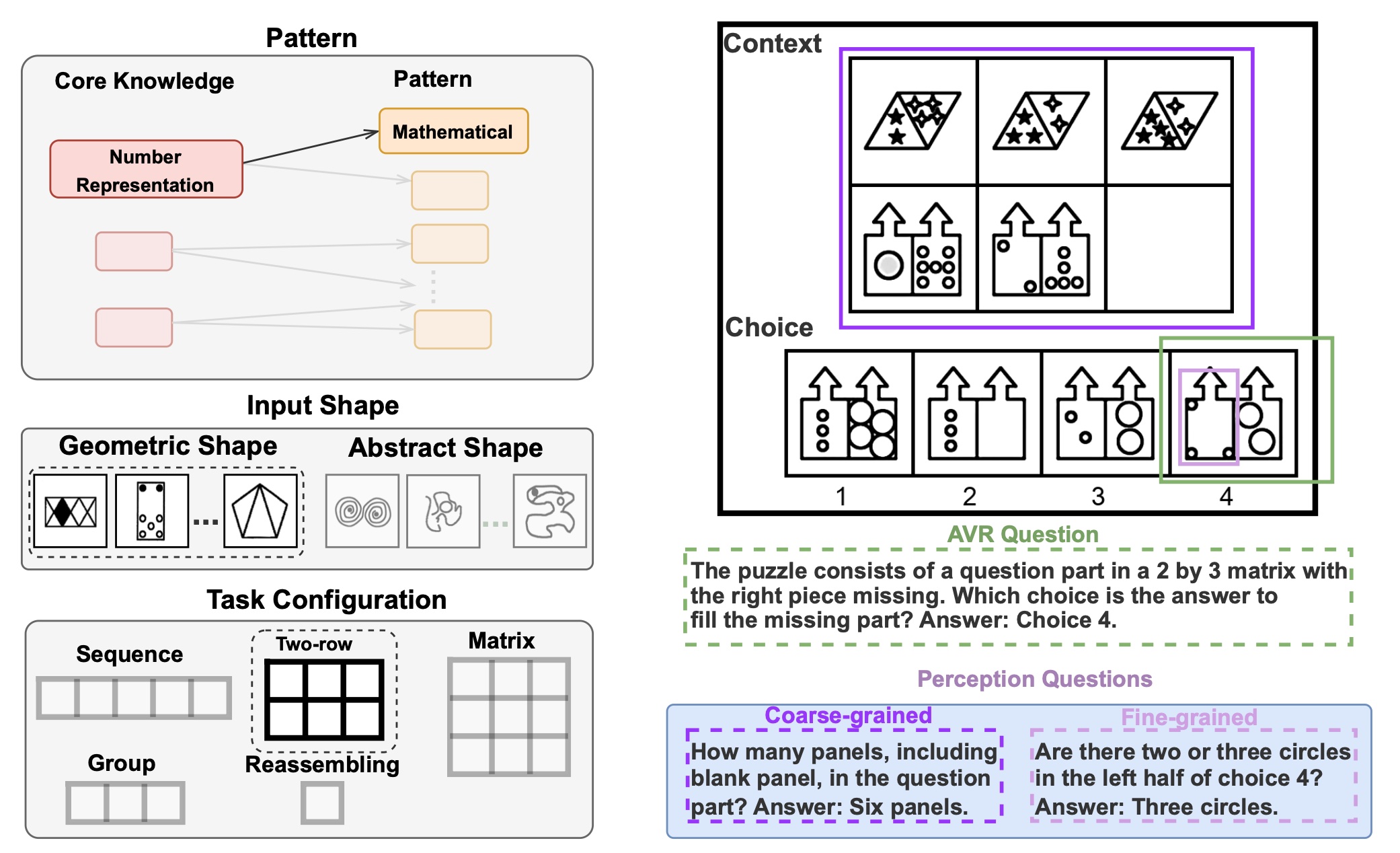
task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR
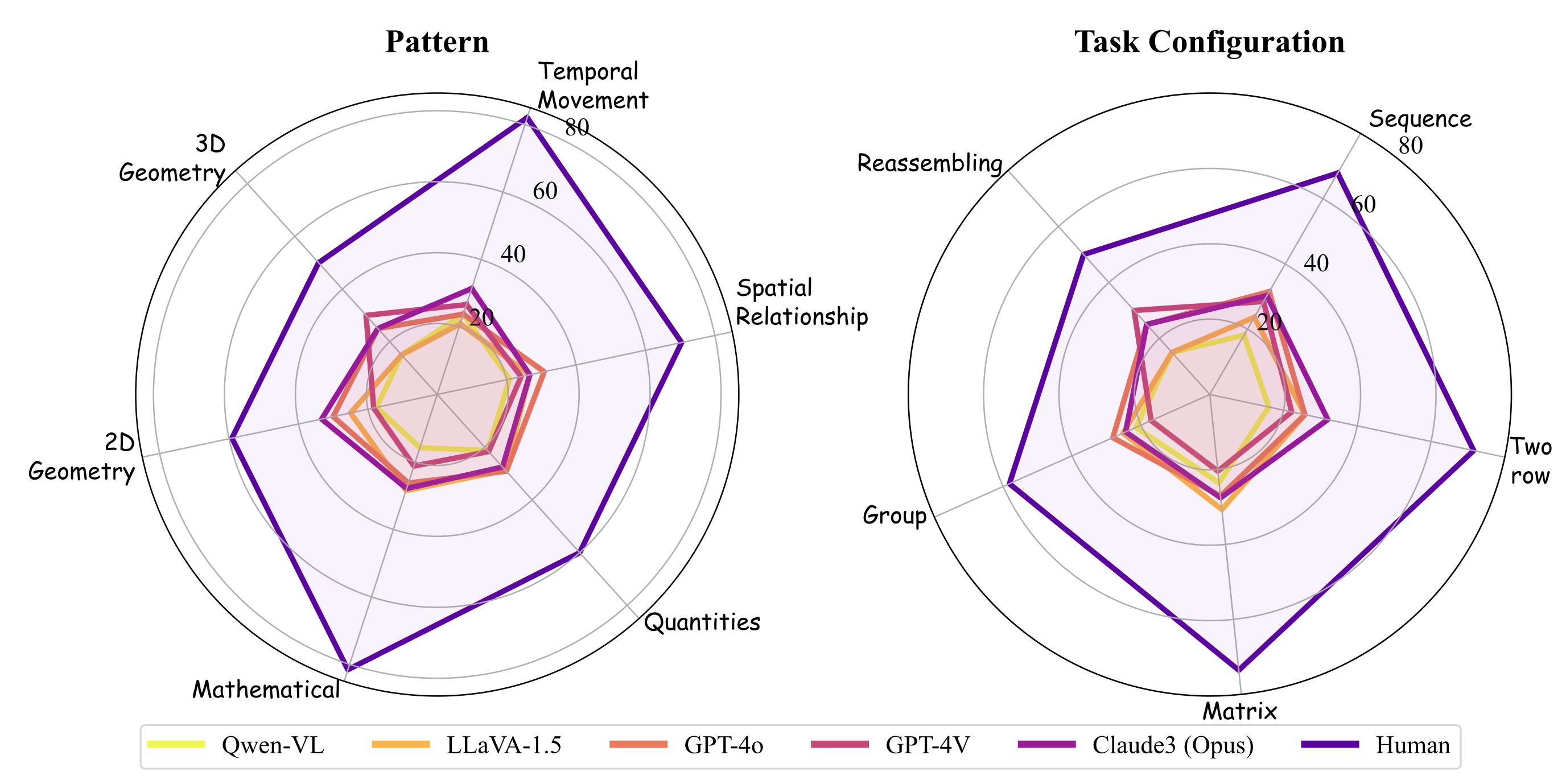
benchmark with 770 puzzles composed of six core knowledge patterns,
geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning,
MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive
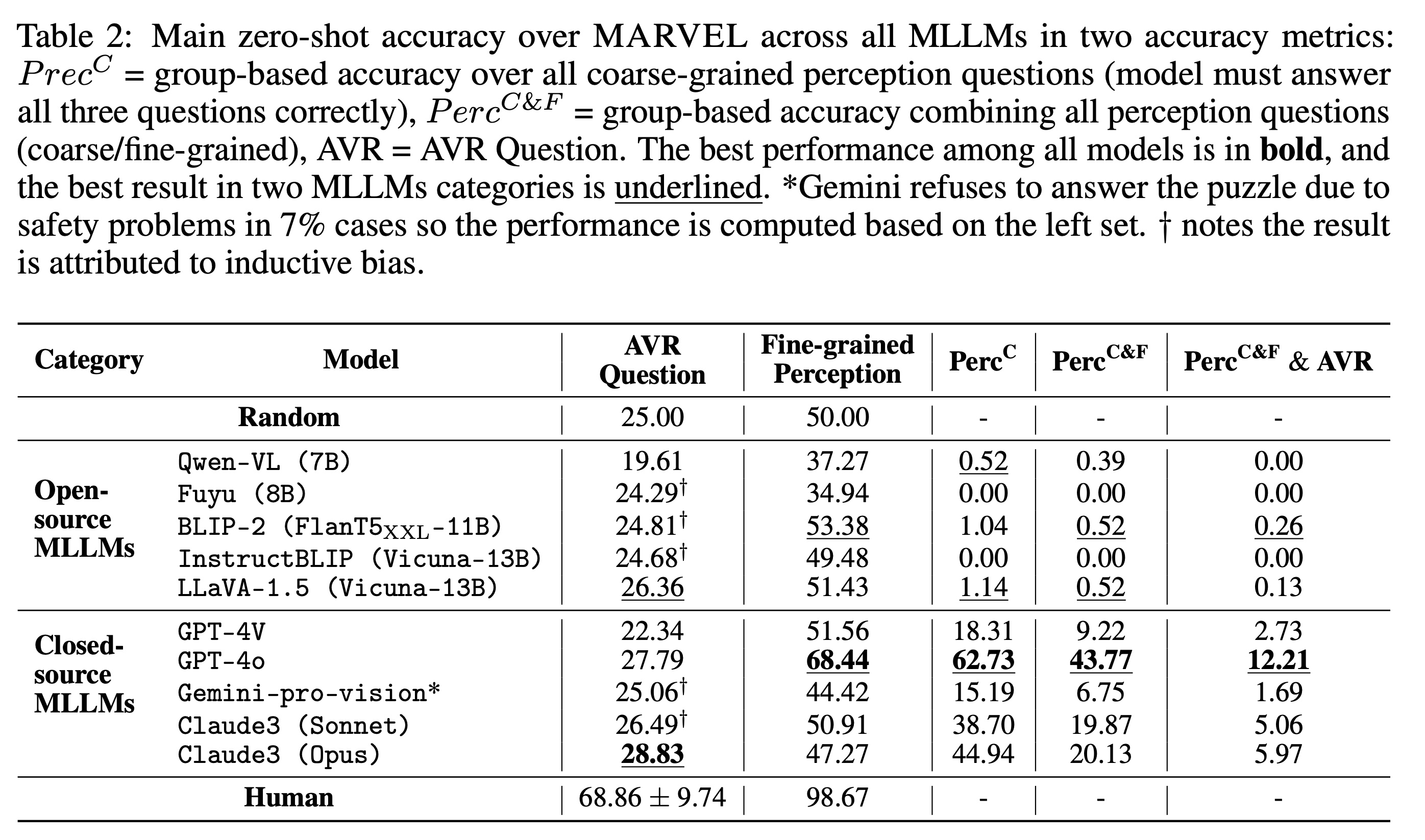
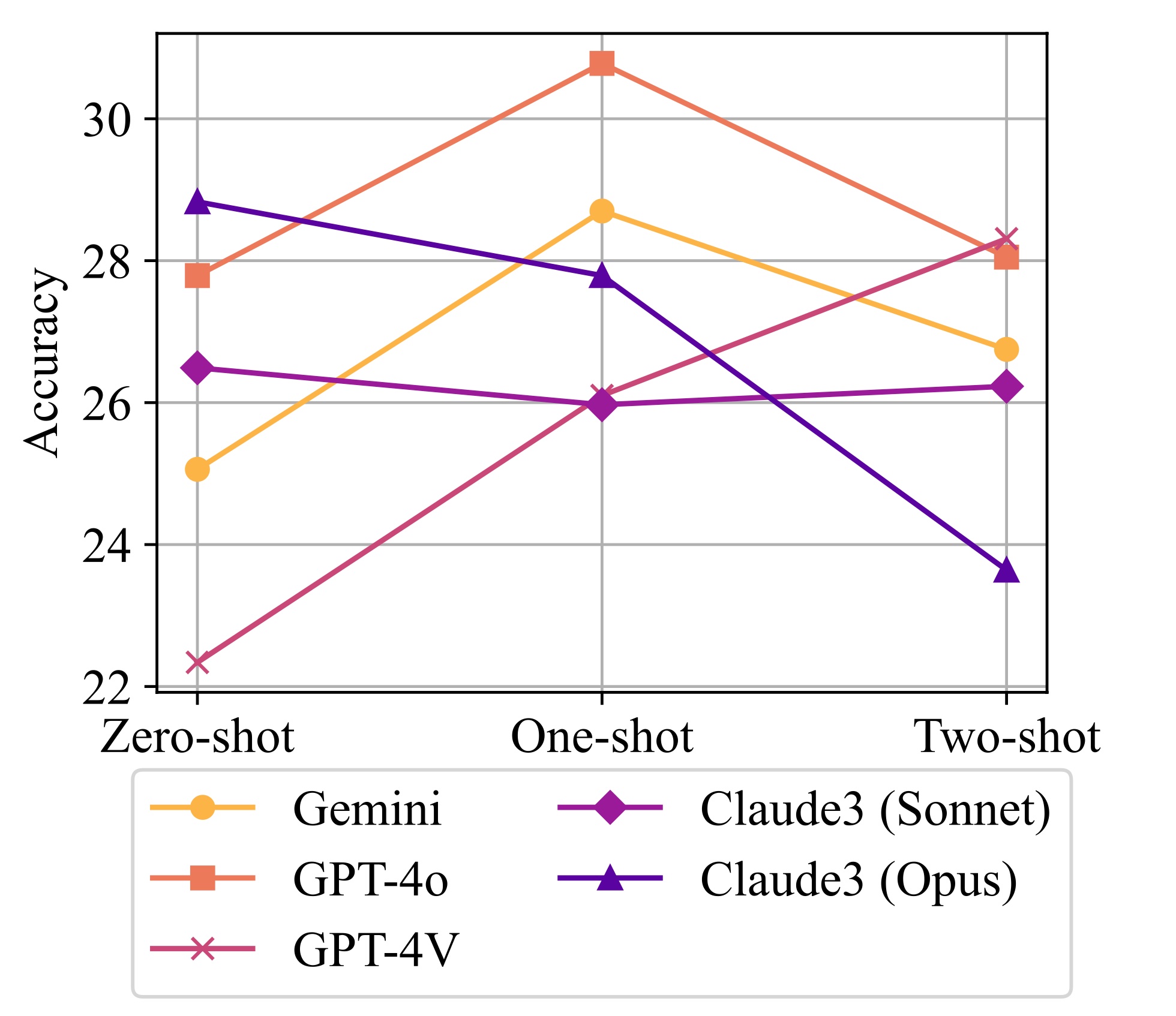
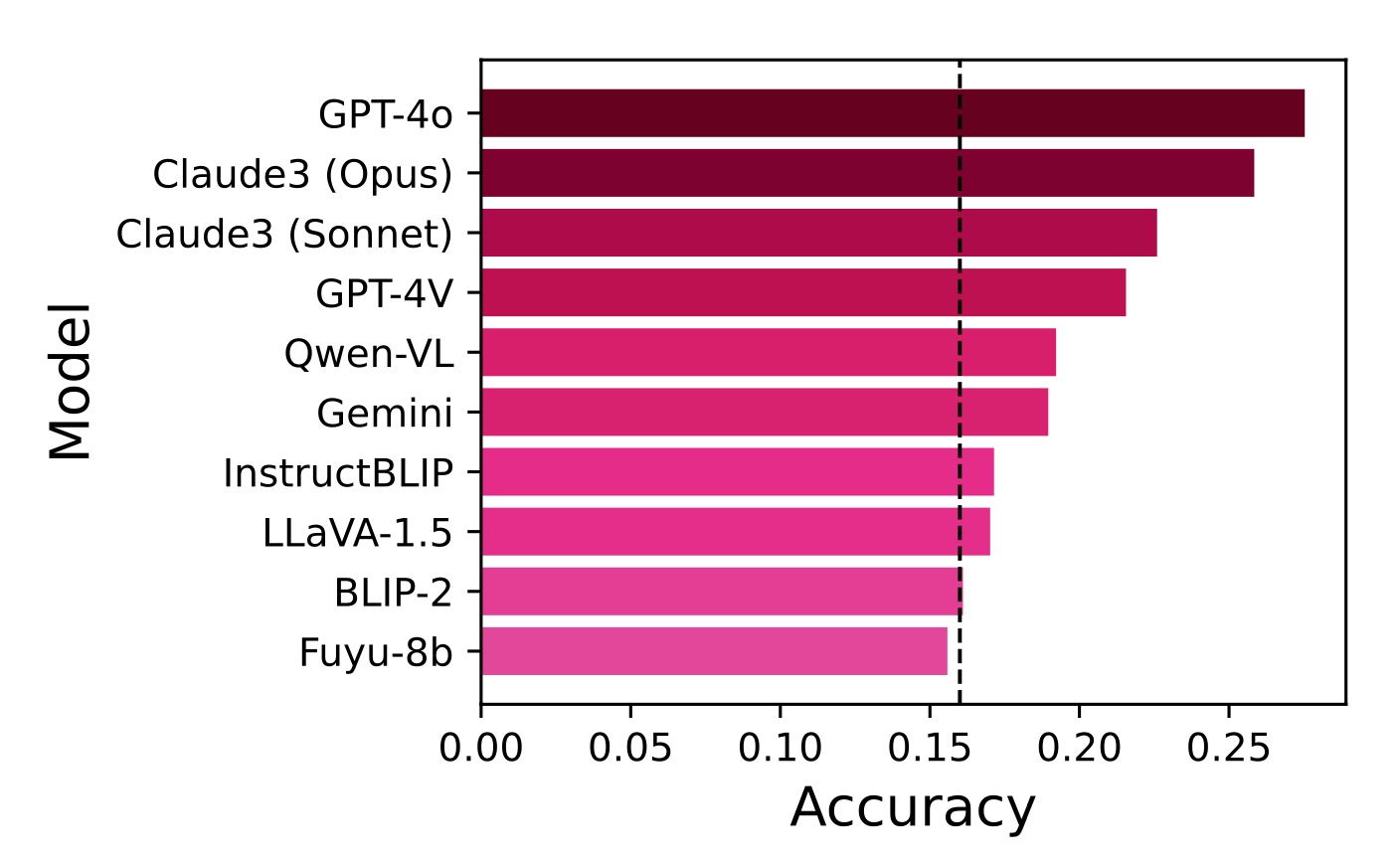
experiments on MARVEL with nine representative MLLMs in zero-shot
and few-shot settings. Our experiments reveal that all models show nearrandom performance on the AVR question, with significant performance
gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle
to comprehend the visual features (near-random performance) and even
count the panels in the puzzle (<45%), hindering their ability for abstract
reasoning. We release our entire code and dataset.